Why are K8s upgrades so tough?
2023-05-11
Why are K8s upgrades so tough?

🥐 Platform Weekly here! You know that feeling you get when you flip your pillow to the cold side in the middle of the night? Reading us is better than that.
Let’s get bakin’
What makes K8s upgrades so challenging?
Text by Fawad Khaliq, Founder and CTO at Chkk
Memes by Luca Galante
Our last 100+ conversations with DevOps/SREs are summarized in 4 nouns and 3 emotions: “Kubernetes Cluster Version Upgrades”…. “Hard, Pain, Work”.
Why are Kubernetes upgrades so challenging? Why isn’t a Kubernetes upgrade as easy as an iPhone upgrade experience? Here’s what makes it hard and why DevOps/SREs find change management stressful:
1️⃣ Kubernetes isn’t, and shouldn’t be, vertically integrated.
K8s is designed for flexibility and cloud providers work hard to ensure this flexibility isn’t compromised.
💡The solution is a cloud-owned k8s control plane (EKS, GKE, AKS, OKE …) with a few managed add-ons (e.g. CoreDNS, CNI …) and some guidance on how to build apps, while giving the flexibility of introducing new components/add-ons/apps to DevOps/SRE teams.
The cost of this flexibility is that these DevOps/SRE teams must now own the lifecycle of the add-ons and the applications that run on top of the k8s infrastructure.
2️⃣ You don’t know what’ll break before it breaks.
With so many moving pieces, it’s hard to know if your running k8s components have incompatibilities or latent risks.
Many users use spreadsheets to track what they are running vs what they should be running, which is both painful and error prone.
We all know that “Not broken != working-as-it-should”. Latent risks and unsupported versions may keep lurking around for weeks/months until they cause impact.
What’s needed here is sharing the collective knowledge of the DevOps/SRE teams, so if one team has encountered an upgrade risk then everyone else just gets to avoid it without any extra work on their end.
Using spreadsheets to track what's running on k8s be like:

3️⃣ Getting an upgrade right takes a lot of time.
Deloitte’s CIO survey estimates that 80% of DevOps/SRE time is spent in operations/maintenance, and only 20% is spent on innovation.
I am not surprised as cooking up a “safe” upgrade plan is a huge time sink. You have to read an inordinate amount of text and code (on release notes, GitHub issues/PRs, blogs, etc.) to really understand what’s relevant to you vs what’s not.
This can take weeks of effort, which is time that you could’ve spent on business critical functions like architectural projects and infrastructure scaling/optimization.

Fawad is the Founder and CTO at Chkk - a company focused on eliminating operational risks through Collective Learning. Formerly, he was a technical lead for Amazon EKS, and early engineer at PLUMgrid, creators of eBPF. You can follow him on Twitter @fawadkhaliq.
Read the full article here.
Is the era of microservices over?
Lambda and serverless were touted by AWS to be the future, but even their own engineers disagree.
Last week, an Amazon Prime Video case study stirred up some controversy when the team revealed they had reduced costs by 90% by moving from microservices back to a monolith: “Microservices and serverless components are tools that do work at high scale, but whether to use them over monolith has to be made on a case-by-case basis.”
It’s surprising to some because AWS frequently frames microservices and serverless architecture as the best way to modernize applications.
But it also isn’t surprising (or, at least, it shouldn’t be 😬) that some architectures work well for some businesses but not for others.
Amazon Prime Video’s old architecture was based on Amazon Lambda, which is good if you want to build services quickly. However, it wasn’t cost-effective when running at high scale. Let’s take the orchestration workflow, for example. Alex Xusuccinctly explained that “AWS step functions charge users by state transitions and the orchestration performs multiple state transitions every second.”
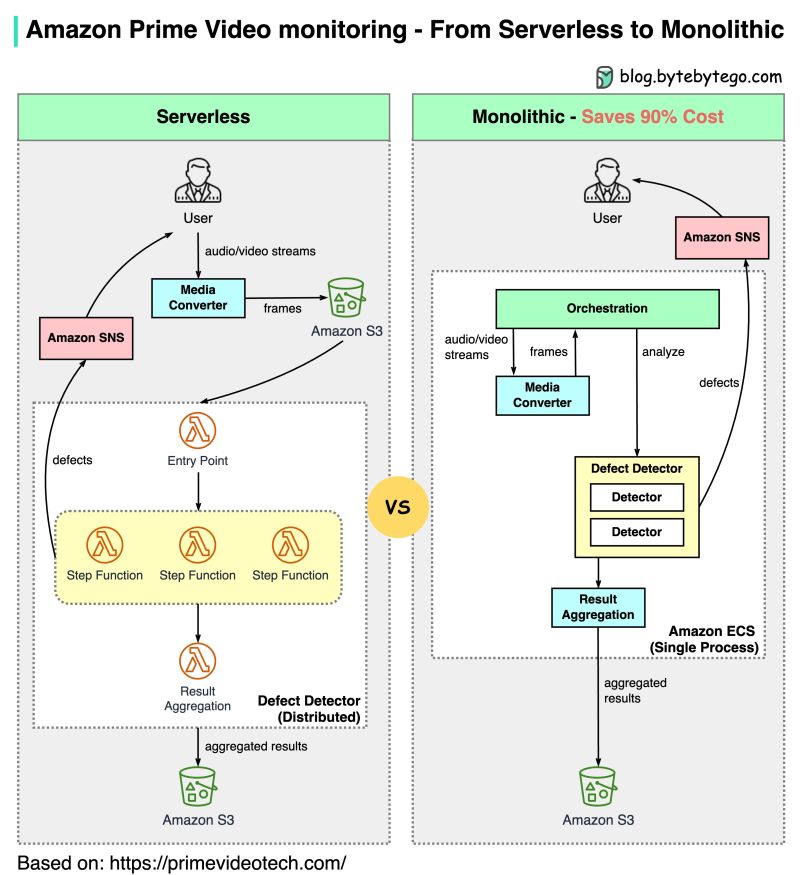
Furthermore, in the old architecture, intermediate data was stored in Amazon S3 before it was downloaded. High volume downloads became très cher 💸.
A monolithic architecture is supposed to address these cost issues. From Alex Xu, again: “There are still 3 components, but the media converter and defect detector are deployed in the same process, saving the cost of passing data over the network.”
And that’s where the 90% cost reduction came from! Pretty neat, right?
So the next time someone tells you “microservices good, monoliths bad” (or “monoliths good, microservices bad” for that matter), kindly send them this newsletter. 😉 And remember: your business should determine your architecture, not the other way around.
Have you joined the Platform Engineering Slack channel? If not, you're missing out. Join us to weigh in on some open questions:
Stay crunchy 🥐
Luca